BonsaiDb v0.2.0: Custom Primary Keys, LZ4 Compression
Written by Jonathan Johnson. Published 2022-02-18.
What is BonsaiDb?
BonsaiDb is a new database aiming to be the most developer-friendly Rust database. BonsaiDb has a unique feature set geared at solving many common data problems. We have a page dedicated to answering the question: What is BonsaiDb?.
I'm excited to announce v0.2.0, which brings two major features in addition to many small improvements and fixes. There are API-level changes that are potentially breaking changes. The CHANGELOG should help navigate through the changes necessary to update your projects.
Custom Primary Keys
One design decision that was made early in BonsaiDb's development was to use a u64 as the unique id/primary key for all documents. This was largely done to simplify the API, and I felt like it was reasonable that users could create an alternate key using a unique view.
I've attempted twice before to change it to allow customizing the primary key, but each time I ended up reverting the changes as I didn't like the impact to the API. However, this time I've succeeded in adding this API with minimal impact to the high-level API.
Our new example demonstrates how this feature can be
used with the Collection derive macro:
#[derive(Debug, Serialize, Deserialize, Collection, Eq, PartialEq)]
#[collection(name = "multi-key", primary_key = (u32, u64))]
struct MultiKey {
value: String,
}
async fn test<C: Connection>(db: C) -> anyhow::Result<()> {
let inserted = MultiKey {
value: String::from("hello"),
}
.insert_into((42, 64), &db)
.await?;
let retrieved = MultiKey::get((42, 64), &db)
.await?
.expect("document not found");
}
The way this is implemented, any type that implements Key trait and
isn't too large can be used as a primary key. The current size limitation is
purely for optimization, and may be relaxed in the future.
More information about this feature can be found in our user guide.
LZ4 Compression
A potential user was originally trying to diagnose why BonsaiDb was creating
larger databases than Sled. After some troubleshooting, it was discovered that
they had enabled the zstd feature in Sled, enabling automatic compression of
data being stored.
This was a feature I had already planned on supporting, although my research had
led me to believe that LZ4 was a better choice for an algorithm. Without doing
comparative benchmarking personally, I decided to start with LZ4 compression and
add zstd once namespaced features are released in Rust.
Some benchmarks have been updated to include compression for comparision. The results are interesting to look at, but no serious comparisons should be drawn yet. If you are under tight space constraints, this feature can save a lot of storage space while not impacting performance in a major way.
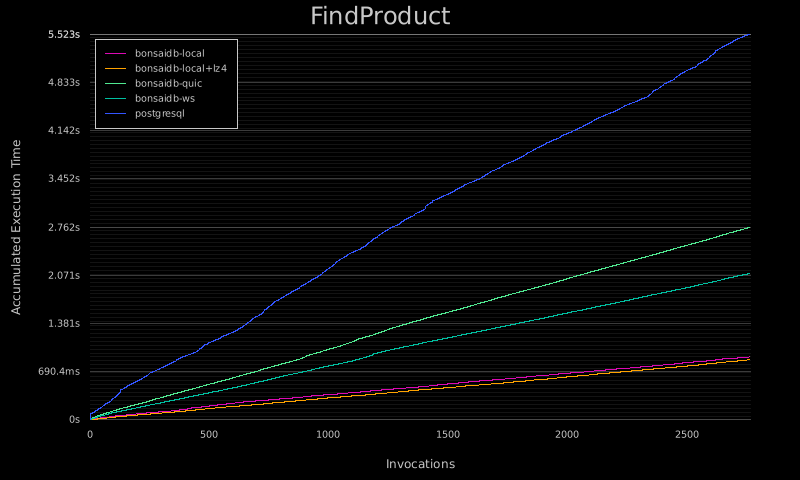
As you can see in this graph, the Commerce Benchmark sometimes shows improved performance over the uncompressed version. As always, performance will depend on your hardware and operating environment, which is why this is an opt-in feature.
The user who originally asked about this feature had reported that BonsaiDb's uncompressed database size a staggering 30x larger than the equivalent data in Sled. The next day they were able to test a branch with the feature enabled. The BonsaiDb database compressed with LZ4 shrunk to under half the size of their Sled database.
Getting Started
Our homepage has basic setup instructions and a list of examples. We have started writing a user's guide, and we have tried to write good documentation.
We would love to hear from you if you have questions or feedback. We have community Discourse forums and a Discord server, but also welcome anyone to open an issue with any questions or feedback.
We dream big with BonsaiDb, and we believe that it can simplify writing and deploying complex, data-driven applications in Rust. We would love additional contributors who have similar passions and ambitions.
Lastly, if you build something with one of our libraries, we would love to hear about it. Nothing makes us happier than hearing people are building things with our crates!