BonsaiDb v0.4.0: Now available without async
Written by Jonathan Johnson. Published 2022-03-29.
What is BonsaiDb?
BonsaiDb is a new database aiming to be the most developer-friendly Rust database. BonsaiDb has a unique feature set geared at solving many common data problems. We have a page dedicated to answering the question: What is BonsaiDb?. All source code is dual-licensed under the MIT and Apache License 2.0 licenses.
BonsaiDb v0.4.0 has been released with a new blocking (non-async) API, better identity/authentication session management, and many other improvements. The full list of changes can be viewed on the GitHub Release page.
For readers who enjoy the "This month in BonsaiDb" updates, this release announcement takes the place of that post this month.
Updating existing projects
This update contains no changes to how data is stored. However, there are a large number of types that have been renamed to distinguish async types from blocking types.
If you have an existing project and want to continue using async, here are the types that you need to find and replace with their async counterparts in your project:
| Crate | Blocking Type | Async Type |
|---|---|---|
| Core | Connection | AsyncConnection |
| Core | StorageConnection | AsyncStorageConnection |
| Core | PubSub | AsyncPubSub |
| Core | Subscriber | AsyncSubscriber |
| Core | KeyValue | AsyncKeyValue |
| Core | LowLevelConnection | AsyncLowLevelConnection |
| Local | Storage | AsyncStorage |
| Local | Database | AsyncDatabase |
After changing these types, you might encounter errors with functions like
SerializedCollection::push_into or SerializedCollection::list. In every
situation that this happens, you should be able to simply add _async to the
function name. For example, SerializedCollection::push_into_async is the async
version of SerializedCollection::push_into.
If you are using the local version of BonsaiDb, Tokio has become an optional dependency. To enable async, enable the appropriate feature for whichever crate you're importing:
bonsaidb = { version = "0.4.0", features = ["local", "local-async"] }
bonsaidb-local = { version = "0.4.0", default-features = false, features = ["async"] }
There are other small breaking changes which are unlikely to affect most users. The full list can be viewed in the CHANGELOG or release page.
For those it might help, I've updated an example project of mine from v0.2 to this new release. The changes can be viewed in this commit. This project features a client/server workspace and uses BonsaiDb's custom API functionality.
Why introduce a blocking API?
BonsaiDb has always wrapped Nebari's blocking API with tokio::task::spawn_blocking and exposed an async API. The reason behind this initial design was that the local-only version of BonsaiDb was a convenience feature, and the "real" benefit of projects adopting BonsaiDb was to use its server mode (and eventually clustering mode). I believe strongly that async is the best way to design a server that has long-lasting connections, and the types of applications I envision being developed with BonsaiDb fit that access model: Remote PubSub, Server-Push Apis, and more.
One day I was joking that a friend wouldn't want to use BonsaiDb for his project because it would force him to use async. While he proceeded to say that async wouldn't stop him, the exchange made me take stock of the current users of BonsaiDb. Of all the people who I know are using BonsaiDb, most were only using the local version and many weren't building networked applications.
Case in point, one user was painstakingly porting their project to async from sync to be able to use BonsaiDb. Thankfully, this set of changes were already underway, and they were able to be the first external tester of the new blocking API.
How does BonsaiDb enable both blocking and async access?
For the the local implementation, the most direct implementation is the blocking implementation. This means that there will be less overhead on local "connections" using the non-async interface. The overhead of the async types is very low, but it is present, and it is the same overhead that has always been present on BonsaiDb's interface.
The local implementation exposes Storage and
Database, which implement
StorageConnection and Connection
respectively. These types are the blocking types.
AsyncStorage and AsyncDatabase implement
AsyncStorageConnection and
AsyncConnection. These types are the async types that
internally store a handle to the Tokio runtime they belong to. This grants these
types the ability to spawn blocking tasks as needed, even when used in
async code that is using another async runtime.
All local types offer several convenient functions that allow seamless conversion to and from each other, enabling applications that use both blocking and async to use BonsaiDb as their database with ease.
The server implementation currently only exposes an initialization API that is
compatible with async code. Once the server is initialized, however, a
Server/CustomServer instance can be converted to
Storage, enabling blocking access to the underlying storage layer.
The Client type used for accessing a server implements both
StorageConnection and AsyncStorageConnection, except for on WASM where no
blocking implementation is provided. Currently, all networking implementations
require Tokio to drive their networking behind the scenes, but in the future
alternative implementations are possible to remove the reliance on Tokio for the
network client.
Improved authenticated session handling
Prior to this release, there was no way to enforce database permissions in the offline version of BonsaiDb. If you are building a multi-user app but are using your own web server, how are you supposed to be able to leverage BonsaiDb's permissions and authentication?
This release addresses this problem by moving all permission checking into the
offline version and adding assume_identity() to
StorageConnection/AsyncStorageConnection. Assuming an identity requires the
permission to be allowed by the current connection. These changes allow all
applications that need multi-user support to use the built-in role-based access
control and, optionally, the built-in password authentication.
Each connection object now has an associated Session, available
through the new HasSession trait. The functions
assume_identity() and authenticate() return a new instance that is
authenticated with the updated identity and associated permissions. The original
connection retains its original authentication. This allows multiple
authentication sessions to coexist on the same underlying connection, regardless
of if it's a local or remote connection.
When opening a local storage/database/server, the connection begins with no
identity and restricted permissions. When connecting to a remote server, the
client's unauthenticated session is limited to the permissions from
ServerConfiguration::default_permissions. After
authenticating a user or assuming an identity,
StorageConfiguration::authenticated_permissions
will be merged with the identity's granted permissions.
I hope to see users trying out BonsaiDb's built-in user management and role-based access control!
Primary Key/View Key improvements
The Key trait has been split into two traits: Key
and KeyEncoding. This split has enabled various queries to
take borrowed representations of the keys. For example, a String key type can
now be queried using an &str:
let doc = MyCollection::get("my key", &db)?;
let mappings = db.view::<MyView>().with_key("my key").query()?;
Additional types now have Key implementations provided for them: [u8; N],
SystemTime and Duration.
Using Time as a Key
Both SystemTime and Duration are stored with the full range that Duration
supports. In memory, these types require 12 bytes to represent, and even with
variable integer encoding, the values encoded as keys can still be fairly long.
Most users don't need nanosecond precision with the range of 42 times the age of
the universe. After a fun coworking session on our Discord server, I
introduced LimitedResolutionDuration and
LimitedResolutionTimestamp. These types allow representing durations and
timestamps using smaller in-memory representations, and offer additional
compression using variable integer encoding and customizable epochs.
To see an example of the benefits, compare timestamps encoded over the span of
the next 40 years and their Key-encoded lengths:
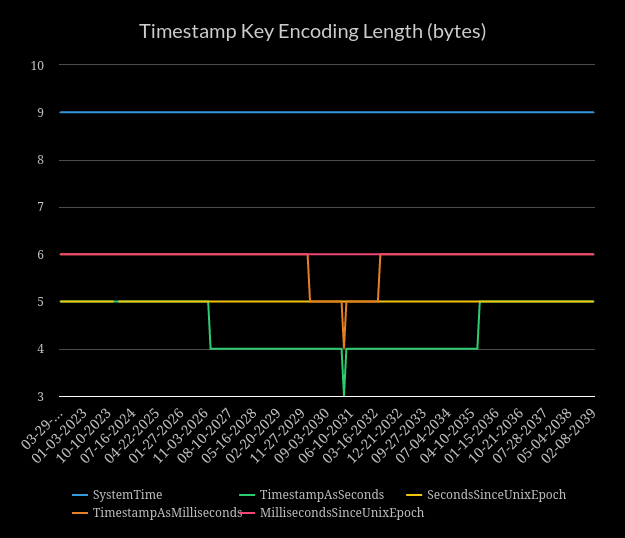
As you can see, SystemTime encodes as 9 bytes (and will continue to do so
until year 10,680). SystemTime's Key implementation encodes the duration
from the unix epoch, so this means that Durations that of 52 years with
nanosecond precision take 9 bytes to encode. The smaller the Duration being
encoded, the smaller the output will be.
By using one millisecond resolution, we can reduce the number of bytes down to 6 and also use only 8 bytes in memory to represent the value. By using one second resolution, we can further reduce the key size by another byte.
How can we compress timestamps further? By leveraging an Epoch that is closer to the median of the expected timestamp/duration range, we can allow the variable integer encoding to shine. The closer to the Epoch the timestamp is, the smaller the value is.
In the above chart, the two values that dip in the middle use
BonsaiEpoch. After considering that databases either live long
enough to be used for almost an eternity (PostgreSQL was first released in the
1980s) or live a short life. I thought the 10-year anniversary of the first
commit of BonsaiDb seemed like a good idea.
Despite it being an arbitrary decision, further consideration showed that epoch is good for one reason: Nanosecond-resolution timestamps encoded today will encode as 8 bytes, and will continue doing so until year 2,049. If an epoch slightly farther out were chosen, today's timestamps would encode with a full 9 bytes, offering no benefit over the unix epoch version. This extra byte of savings isn't much, but it does make the key size word size or less on most modern machines.
I've added a full set of types that support resolutions ranging from nanoseconds to weeks, and timestamp types that support both the BonsaiDb and unix epochs. You can also implement your own resolution and/or epoch to tailor fit how these new types work.
Other contributors this release
I wanted to make sure to include a mention for @vbmade2000's contributions to this release. They added the ability to delete users, and the ability to retrieve a list of document headers without fetching the document's contents.
If you are interested in contributing to BonsaiDb, I am trying to keep a healthy list of good first issues.
Getting Started
Our homepage has basic setup instructions and a list of examples. We have started writing a user's guide, and we have tried to write good documentation.
We would love to hear from you if you have questions or feedback. We have community Discourse forums and a Discord server, but also welcome anyone to open an issue with any questions or feedback.
We dream big with BonsaiDb, and we believe that it can simplify writing and deploying complex, data-driven applications in Rust. We would love additional contributors who have similar passions and ambitions.
Lastly, if you build something with one of our libraries, we would love to hear about it. Nothing makes us happier than hearing people are building things with our crates!