Introducing OkayWAL: A write-ahead log for Rust
Written by Jonathan Johnson. Published 2023-01-06.
It's been almost 6 months since the last update on optimizing BonsaiDb. When I last left you, I was optimistic about my in-development "blob storage" layer, Sediment.
The tl;dr is that I struggled to optimize my single-file approach with
Sediment. Specifically, when writing a very small change, the extra overhead of
having to rewrite a few pages on disk would cause my average fsync time to
always be significantly longer than writing a small change to PostgreSQL.
The solution to that problem is what many databases have adopted: write-ahead logging (WAL). Today, I released v0.2 of OkayWAL.
What is OkayWAL?
OkayWAL is my attempt at making an efficient, general purpose WAL implementation for Rust. The primary goal of a WAL is to provide efficient atomic and durable data persistence.
A WAL typically is used in conjunction with another data store -- what I'll refer to as the primary data store. Since updating a primary data store can be a lot of work, it can be faster to serialize a set of changes that are needed to be applied to the primary data store and write those changes to the WAL first.
Why would writing the data to a second location be faster? The primary data store is likely designed for organized storage and quick retrieval of data. Updating the primary data store probably requires updating multiple on-disk data structures which probably live on different pages on disk.
A WAL, however, is designed for one job: persisting bytes to disk atomically as quickly as possible. It can take advantage of many strategies to optimize this operation, keeping average write times small.
Data eventually makes its way from the WAL to the primary data store in an operation usually referred to as checkpointing. The updates to the primary data store can generally be optimized by grouping some or all of the operations being checkpointed into a single update to the primary data store.
How does OkayWAL perform?
As the name implies, it performs "okay." Because of some close cuts with
burnout, I've had to remind myself that my goal isn't to be the fastest database
in the world. I just want to be in the same realm as other general purpose
databases. These benchmark results are from running cargo bench -p benchmarks --all-features inside of the repository. All results are from my
local development machine running Manjaro Linux on a PCIe Gen 3 NVME ext4 drive.
As with all benchmark results, you should always test and verify yourselves on
your own target hardware.
The only benchmark I currently have is writing a fixed sized payload using a variety of thread counts. Here are the graphs showing the average time to perform an atomic and durable write of data to OkayWAL, sharded-log v0.0.1, and PostgreSQL.
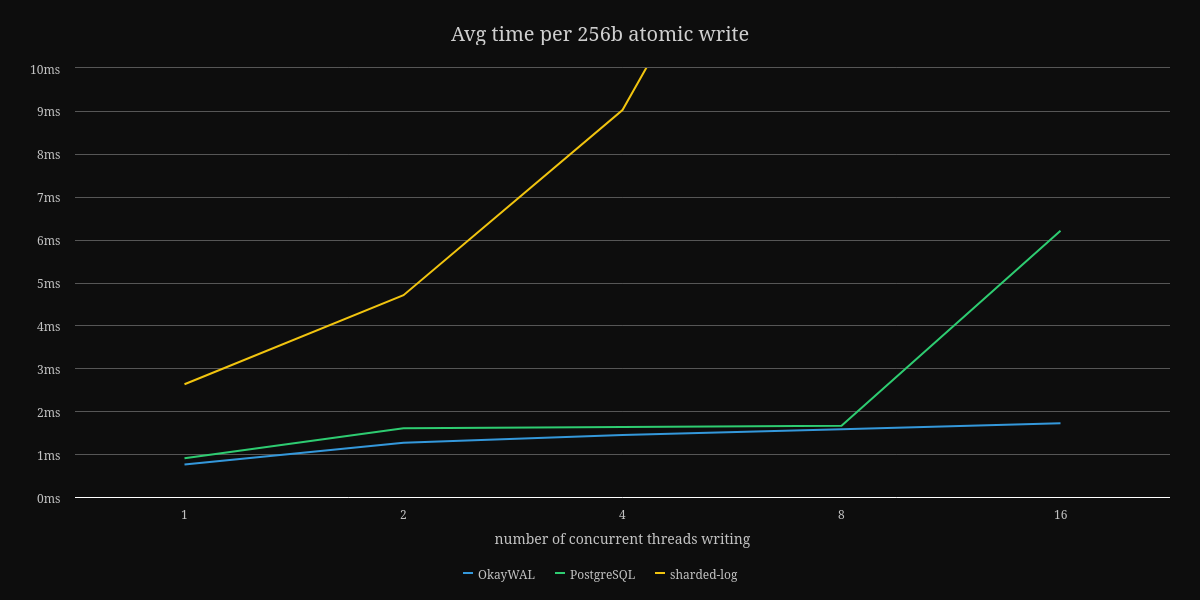
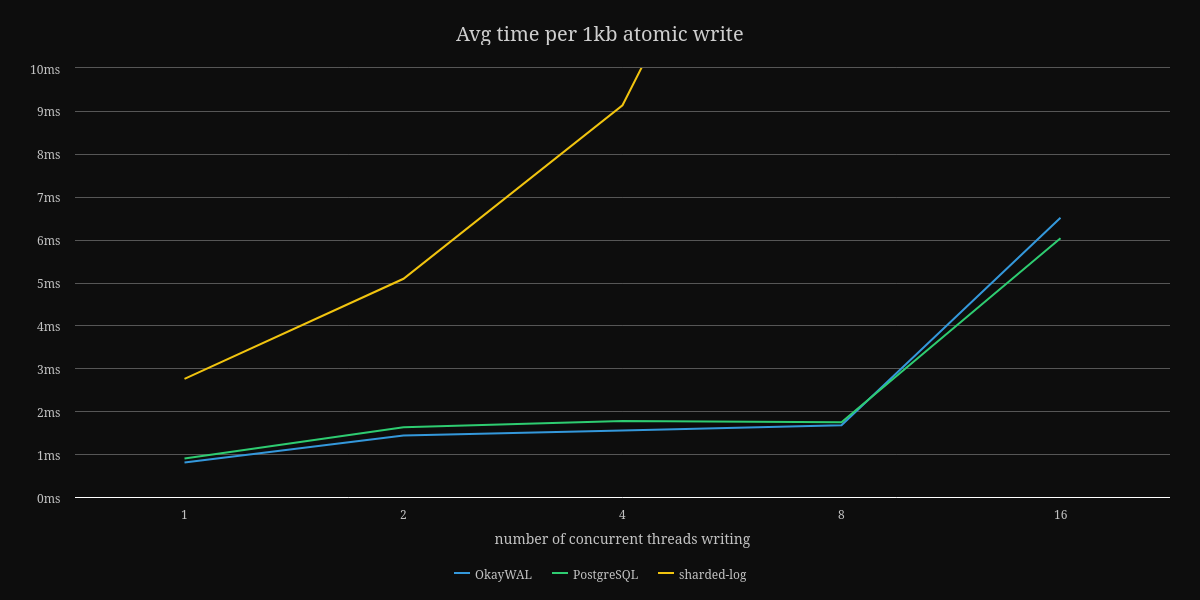
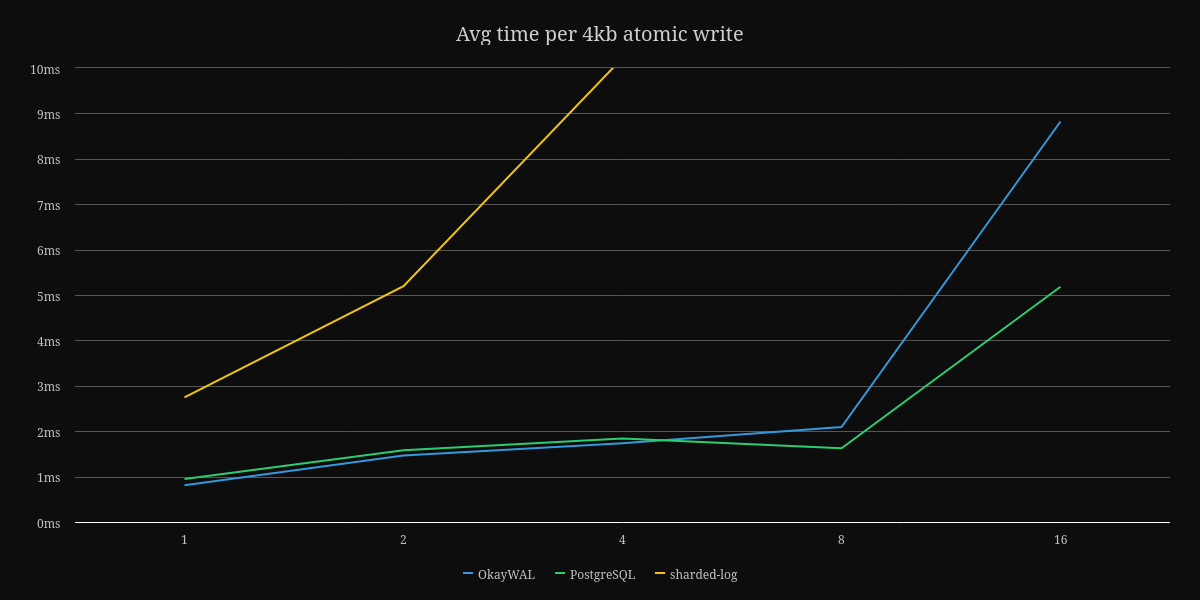
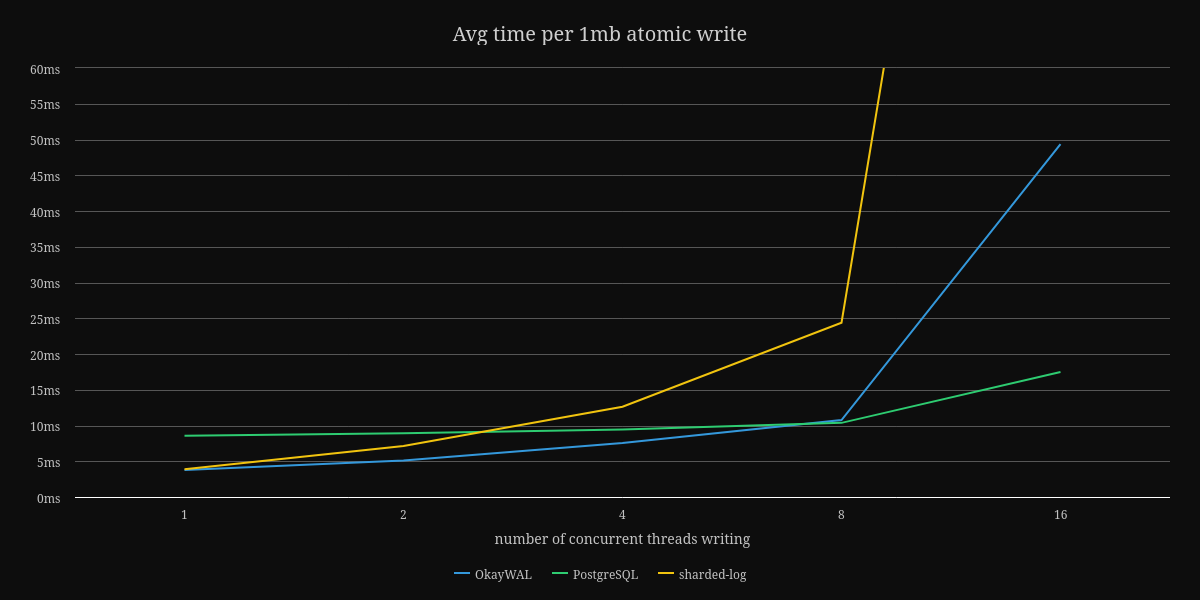
First, a note about sharded-log, a GPL-licensed write-ahead log implementation by the authors of Sled. When I was looking for write-ahead log implementations in Rust, I saw this crate. Sadly, GPL is not compatible with the goals I have of BonsaiDb, so I initially created my own version inspired by their multi-writer design. After some early benchmarking, I ended up throwing out that implementation and switching to a model inspired by how PostgreSQL's WAL works. Given that it's a v0.0.1 release on Crates.io, I wouldn't take its benchmarks seriously, which is why I've cut off the higher end results to keep the comparison against PostgreSQL more legible.
Second, a note about PostgreSQL. I am connecting to PostgreSQL using the
postgres crate over unsecured TCP to localhost. The write is to a
table with a single column: a BYTEA column. From my limited testing, the
overead of the TCP connection is dwarfed by the overhead of fsyncing the data
to disk. My PostgreSQL server has had no customizations to its configuration
beyond whatever my distribution's package manager may have made. Additionally,
PostgreSQL has the added overhead of parsing SQL and performing changes to a
structured database that supports a wide variety of features. While we are
observing PostgreSQL's WAL performance, PostgreSQL is still doing more work than
OkayWAL needs to for each write operation.
Finally, a note about OkayWAL on the 1MB benchmark. The configuration being used is still the default configuration, which only preallocates 1MB and checkpoints after 768KB has been written. This means that the 1MB benchmark is never batching entries, and explains the degradation in performance especially at higher threadcounts. A change in the configuration can help this, but in theory, changes to PostgreSQLs configuration could also optimize its speed for larger payloads as well. This is one area I still want to investigate more rather than just tweak configurations to chase benchmark results.
Why not include a comparison against SQLite? SQLite doesn't have any mechanism for batching multi-threaded writes, as it's designed with single-threaded modifications in mind. While comparing against it in single-threaded benchmarking is useful, all of the multi-threaded benchmarks would be unfair to SQLite as its outside of its intended use case.
Should you use OkayWAL?
Overall, I'm very happy with the state of OkayWAL. But, given how new of a project it is, I can't endorse it for use in production environments yet. If you need a write-ahead log for an experimental project, I would love to hear any feedback you have on this library's design. I don't have a roadmap for OkayWAL, but I am confident I will stabilize it to a v1.0 release during the course of 2023.
How does this fit in with BonsaiDb's optimizations?
Last October, after rewriting OkayWAL I was a little burned out. I never lost
interest in BonsaiDb, but I just couldn't find myself motivated to try
incorporating OkayWAL into Sediment. The mountain of work left to
get the WAL-driven workflow to a point that I could test its performance in
BonsaiDb is quite large. I ended up exploring writing a
#[forbid(unsafe_code)] vm-powered dynamic language, Bud. As someone
who has always loved writing compilers, it was exactly the right type of
distraction to rejuvinate me.
After hosting family for Thanksgiving and subsequently recovering from COVID, I starting pondering how to best approach incorporating OkayWAL into Sediment. After realizing that Sediment was no longer going to be a single-file database given its use of a WAL, I decided to think about whether a multi-file design offered any beneftis.
In the end, I decided upon a new format inspired by the previous design, but split into multiple files. As of yesterday, I finally had the full feature set required by the existing benchmark I had for Sediment. After fixing one fairly obvious oversight in how I was trying to batch transactions, the benchmarks are showing promising numbers. Because I have only done very basic testing, I don't feel comfortable sharing the numbers yet.
However, the basic summary is that even in its unoptimized state, Sediment appears to finally meet the performance goals I need to in theory get BonsaiDb's performance into the same ballpark as other general purpose databases. There is still a lot of work before this work will make its way into BonsaiDb.
If I finally have the right combination of strategies, I think it's realistic to see this new storage system hit BonsaiDb this year. I'm hopeful that I've learned enough on this journey that I will not be left with any major surprises.
Want to follow along more closely?
I've been streaming in the #coworking channel on our community
Discord server fairly frequently. I often post shorter informal
updates on Discord as well, and I've also been trying to be more active on
Mastodon. I always am happy to answer any questions and greatly
appreciate hearing any constructive feedback.