Optimizing BonsaiDb: Improving Transaction Batching (Part 1 of ?)
Written by Jonathan Johnson. Published 2022-05-31.
What is BonsaiDb?
BonsaiDb is a new database aiming to be the most developer-friendly Rust database. BonsaiDb has a unique feature set geared at solving many common data problems. We have a page dedicated to answering the question: What is BonsaiDb?. All source code is dual-licensed under the MIT and Apache License 2.0 licenses.
First, a Thank You
My last post covered how a couple of small but impactful mistakes severely impacted BonsaiDb's performance. The numerous supportive messages and comments I received was truly humbling. Thank you everyone who took the time to reach out in any way.
I had two goals with that post: to let anyone using or considering BonsaiDb know of the issue, and to reassure any users or potential users that I was confident in improving BonsaiDb's performance.
At the time of writing that post, my ideas on how to improve performance were half-formed, and I didn't have any confidence in what sort of speedups I could achieve. I was excited to experiment, but I wasn't ready to share my thoughts.
There are two things that have helped me gain enough confidence to start sharing what I've been working on: the numerous heartwarming messages and comments, and making meaningful progress in testing my ideas.
Today's post covers how I've improved Nebari's transaction batching to be able to achieve a higher number of transactions per second. I will then follow up by discussing how a new format for Nebari might be able to close the remaining performance gap between BonsaiDb and PostgreSQL.
The goal of improving batching
Nebari's current transaction batching supports multiple transactions against different trees (a, b, and c):

In the above example, threads 1, 2 and 3 all begin a transaction against different trees. Because they are all different trees, all threads are able to operate simultaneously. Once a transaction is committed, it must be added to the transaction log. The transaction manager automatically will batch multiple transactions together.
Let's see what happens when these threads all try to modify the same tree instead (a):

Thread 1 acquires the lock on tree a, causing the other two threads to wait until its released. This doesn't happen in Nebari today until the transaction is fully confirmed. This is the problem that the Commerce Benchmark is BonsaiDb was exhibiting: transactions would cause backlogs to form until most workers were blocked waiting on other transactions to complete -- often serially.
What if we could enable this sort of pipelining:

The above sequence of operations still only allows each thread access to the tree for writing one at a time, perserving Nebari's current single-writer philosophy. The transactional guarantees are still the same: no transaction is confirmed complete until it is fully synchronized. The change is in how Nebari is keeping track of the tree states.
Currently, Nebari has a Read and a Write state. The Write state is what is mutated during a transaction. Once a transaction is confirmed, the Write state is published to the Read state. The new method introduces a third state: the committed state. Before unlocking the tree, a clone of the tree's Write state is stored. When the transaction is confirmed, instead of publishing the Write state, the cloned state is published.
This subtle change allows a second transaction to acquire the lock and update the Write state. It too will clone the state and release the tree. If this happened more quickly than the first transaction took to synchronize, even more transactions may proceed and be batched. The only edge case to worry about is that an older state being published should not be able to overwrite a newer state.
This change would enable true Multi-Version Concurrency Control (MVCC) in Nebari's transactions.
I set out on Sunday afternoon to try this new approach.
Initial Results: Pretty good
Yesterday just in time for my lunch break, I reached a point where I could benchmark my new transaction batching code. I am running a specific profile of the Commerce Benchmark using 16 worker agents, which means the database is trying to process requests from 16 threads simultaneously.
| Backend | Total Time | Wall Time |
|---|---|---|
| bonsaidb v0.4.1 | 377.2s | 23.57s |
| refactor from last blog post | 320.1s | 20.01s |
| new approach | 44.91s | 2.807s |
| postgresql | 18.25s | 1.141s |
BonsaiDb v0.4.1 takes ~23 seconds to complete the benchmark. After these changes, it now takes just shy of 3 seconds. This is clearly a huge win. However, PostgreSQL still takes less than half the time, so there's still room for improvement. For those who are curious to dive in beyond the summary, I've uploaded the benchmark report of the new approach.
I compared the timeline view of profiling data in Hotspot:
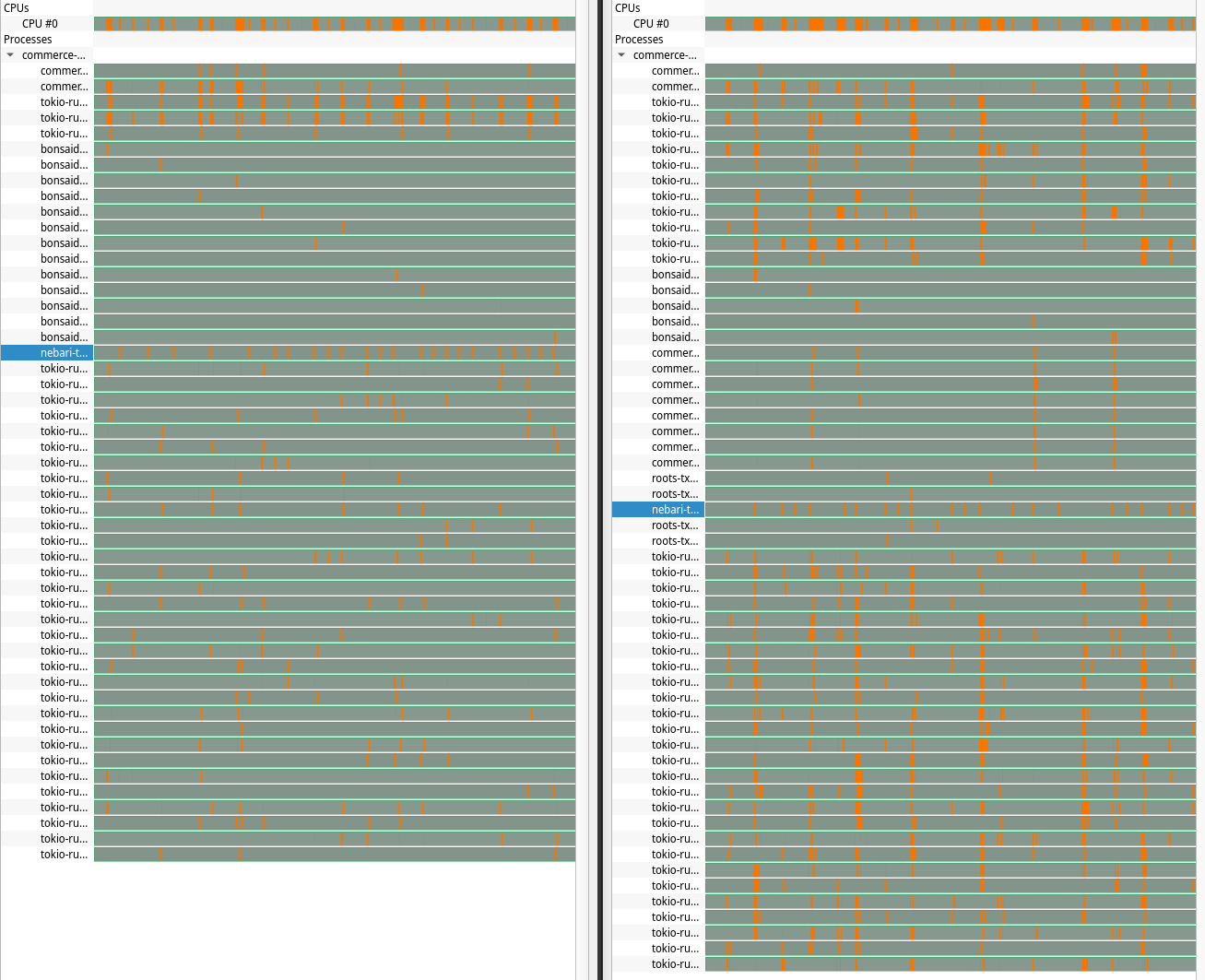
I recognize this image might be hard to read on mobile devices. Clicking the image will allow you to see it at full resolution. Both timelines are zoomed in to show 100ms of activity. On the left is BonsaiDb v0.4.1 and on the right is the updated code.
The orange colored parts are where CPU samples were taken. The green areas are where those threads have no samples -- they were blocked. It's clear at a quick glance that there are a lot more orange areas on the right side, which is what we'd expect given the higher throughput.
The other observation to note is the transaction log's thread activity. Theoretically, that thread's activity should be roughtly the same, as it was and still will be bottlenecked by file flushing. The thread that is highlighted blue is the transaction log thread. While there is variation between the graphs, the amount of activity and the space between them is roughly the same on average. That is exactly what I was expecting to see.
Now, Nebari is bottlenecked by the frequency of flushes, and the Commerce Benchmark is reaching its performance limit due to only having a fixed number of worker agents. Once all agents are waiting on a transaction, everything is blocked until the next batch is committed.
Where's the remaining performance
One challenge that Nebari faces with the current format is that the transaction log does not record which trees were involved in the transaction. If we can't guarantee that all trees are fully flushed before we write the transaction log, we need some way to know upon loading the transaction log that the latest log entry is valid. Because we don't currently have a list of trees in the log itself, there's no way for the log to validate the latest log.
This is why the transaction log requires that all trees are fully flushed before being written itself. If the log format were changed, we could add a list of committed trees to each entry. This would be all that's needed to allow Nebari to perform a single flush per transaction batch, which should nearly double the throughput with the current design. However, I suspect that wouldn't be enough to fully match PostgreSQL's performance.
PostgreSQL, as well as many other database engines, pre-allocate chunks of storage rather than appending to the end of the file for each write. Additionally, when data is freed, other engines will often reuse that space. In the previous blog post, I included some results from a benchmark showing how preallocating can drastically reduce overall write times.
Converting Nebari into a format that can preallocate yet still remain append-only is one approach, but I'm not certain it's worth the effort. Because the above changes necessitate a format upgrade, I feel like my best option would be to re-evaluate my options for how Nebari works to try to achieve the best results.
Designing a new storage format for Nebari
Despite Nebari being designed as an append-only format, the majority of the code
base interacts with the file using two functions: read_chunk() and
write_chunk().
write_chunk() writes a series of bytes to the file and returns a u64. This
number is the offset into the file that the data is stored at, but all of the
B+Tree code treats this number as an opaque ID. The only way it is used is with
subsequent calls to read_chunk().
Because this abstraction exists, it seems pretty clear that the new format's API should look something like:
- Ability to write one or more chunks of data in parallel with other writers, with each chunk of data being assigned a unique id.
- Ability to ask for all the pending writes to be flushed.
- Ability to store a "root" header.
- Ability to retrieve a previously stored chunk of data using its id.
My overall goals of this new underlying storage layer would be:
- Uses a single flush operation for integrity.
- Supports multiple concurrent readers and writers.
- Preallocates disk space in chunks.
- Disk space can be released and reused.
If such a format could be built, it would be a fairly trivial operation to port Nebari to it.
Sediment: A new foundation for Nebari
Sediment is my mostly-still-theorized file format that is aimed at providing the API and goals outlined above.
Sediment will use a single-file architecture that allows storing blobs of data
with ACID compliance. Each stored blob is assigned a GrainId which can be used
to retrieve the data or release the data in the future.
Sediment follows my neverending need to name things in cute but meaningful ways.
The file is organized into a hierarchy of Basins, Stratum, and Grains. A
GrainId identifies which grain inside of which stratum inside of which basin
the data is stored.
Nearly ever header stored in the file will be stored twice. When a new set of updates are being written, new data only touches the outdated copy. There are multiple validations that can happen to ensure that each page touched by a commit was flushed. This design is how Sediment will be able to use a single flush operation to persist a batch of writes to disk.
Once a GrainId has data, it is immutable. The only two operations that can be
performed on a GrainId are: get and archive.
Archiving a grain will prepare the grain to be reused. Grains are not
immediately freed, however. Instead, Sediment assigns each commit a
SequenceId. Sediment supports a built-in log that could be used to power a
replication log. To ensure data is not overwritten before a consumer of the log,
Sediment will allow the user to checkpoint the log to a specific SequenceId.
Once the SequenceId of a given archive operation has been checkpointed, the
GrainIds will be marked as free and be able to be reused.
Will this make BonsaiDb fast again?
I don't expect the result of this to be that BonsaiDb is suddenly faster than PostgreSQL. The reason is simple: when I first saw the benchmark results in January, it took me a very long time convincing myself the PostgreSQL numbers were correct before I allowed myself to get excited.
I had never heard that PostgreSQL is slow -- quite the contrary. From my understanding, if your workload is properly optimized, it's actually a very performant database. I know there are ideas on how to improve its performance, but overall, performance is not usually not people's main complaint with PostgreSQL and performance is continually improving with each release.
I'm not going to be able to achieve anywhere near the numbers reported in January -- they were based on truly flawed processes and methodology. But, I'm hopeful I can get close enough to other ACID-compliant database engines that most users shouldn't have issues with BonsaiDb's performance moving forward.
Why not ship what I have?
The problem with the current set of changes is that they are a complete format change from v0.4.1. While Nebari's format hasn't changed today, BonsaiDb is now using Nebari completely differently. This means that I need to design an upgrade process to migrate the file format.
With my confidence level gaining in my new format's design, I am not very tempted to subject users to two format upgrades. While this decision means that these performance updates will take longer to get into users hands, it means less legacy code for me to support during the alpha period. At this stage in BonsaiDb's development, I have to prioritize maintainability.
I'm excited
While it would have been nice to have been able to work on other features the last few weeks, I'm truly excited by the prospect of this new format. One of the biggest gotchas of benchmarking BonsaiDb (before the recent issues) was the caveat that a "compact" operation had to be performed to reclaim disk space.
With this new format, there will no longer be that caveat. There will still be maintenance tasks that can be performed to try to optimize storage, but they will be optional and shouldn't be necessary in normal operation.
I'm simultaneously relieved and excited that I should be able to stick with Nebari. The changes in my pending view and document storage rewrite enable some really cool features:
- When indexing a view, Nebari's B+Tree now embeds a the view's reduced value at each B+Tree node. This will enable reduce queries across ranges to be optimized and not require accessing as much data when computing the results.
- Document revisions are now based on Nebari's SequenceId. This change opens the path for exposing full document revision history, including a list of every change across the entire collection -- a feature Nebari supported but BonsaiDb did not have a way to expose efficiently.
Nebari's ability to embed your own indexes in the B+Tree nodes and create custom tree roots make it a unique low-level database offering.
What's next?
This post and the last post provide a good summary of what I've been up to for the past month, so I'm skipping a "This Month in BonsaiDb" post for May. If I don't have any news before the end of June rolls around, I'll make sure to write an update covering my progress.
In the meantime, if you'd like to try the current alpha of BonsaiDb, the homepage has basic setup instructions and a list of examples. I have started writing a user's guide, but I think the documentation is in a better state at the moment.
Thank you again to everyone who took the time to write a note after last week's blog post. I'm thankful to be part of such a supportive community.